VAST Data Platform
すべてのデータのためのオールフラッシュストレージ
Overview概要
VAST Data Platform
VAST Dataのコンセプトはすべてのデータを格納し、そのデータにおける最適な活用までを見据えた基盤づくりを実現することです。組織のデータは肥大化の一途をたどっています。これと比例するようにデータの価値は、資産と呼ばれるほど上昇しているのも事実です。これからの時代データを最適に管理・活用していくうえで、VAST Dataはこれまでのストレージにはない全く新しいアーキテクチャーを開発しています。さらにVAST DataはAI時代に最適なストレージプラットフォームを提供します。
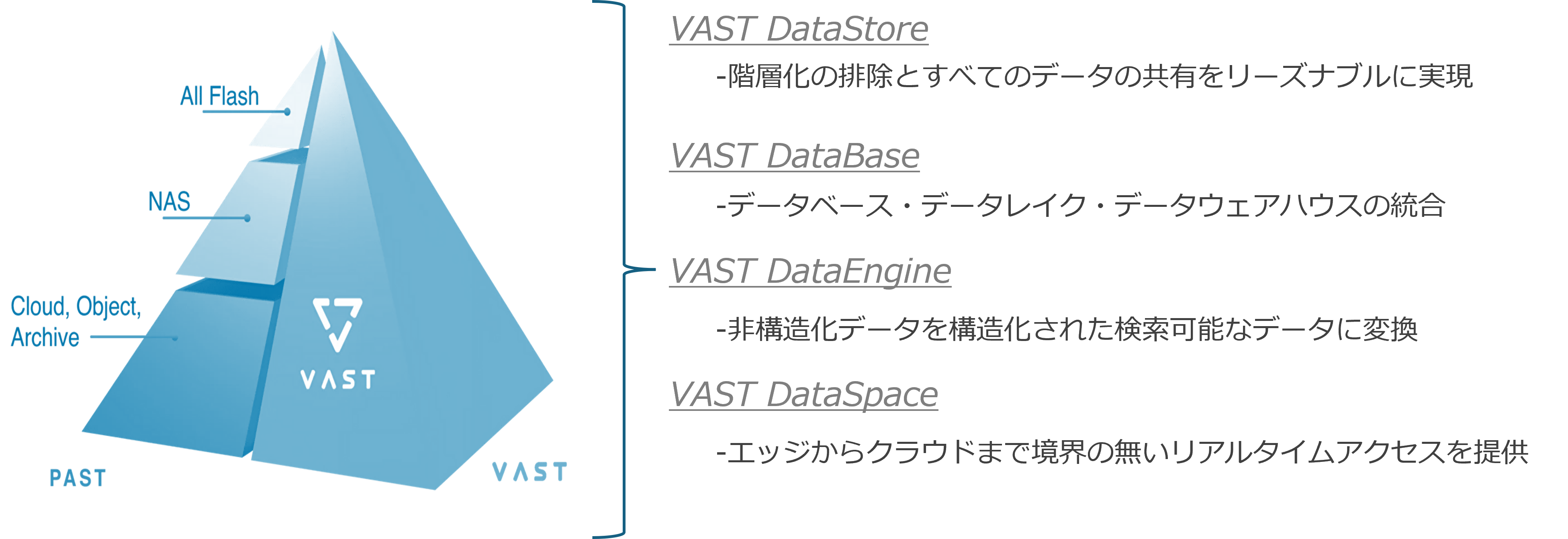
最適化されたアプリケーション
● 人工知能
GPUサーバとRDMAアクセラレーションを用いると、一般的なNASより4倍高速にデータアクセスが可能です。またすべてのデータをフラッシュ上に格納し、HDD遅延をなくします。
● コンテンツ作成
オールフラッシュNASをアーカイビングストレージと同等価格で準備し、すべてのワークフローを高速化します。
● コンテンツ提供
コンテンツデリバリネットワーク企業およびケーブルテレビ事業社のサービス遅延をなくし、エクサバイトのコンテンツをフラッシュから提供可能です。
● データ保護
エンタープライズバックアップはさらに効率化され、リカバリが高速化し、必要とされるデータセンターのファシリティを抑えることができます。
● HPC
近代のNASプラットフォームのシンプルさと、パラレルファイルシステムのパフォーマンスを持ち合わせます。
● ライフサイエンス
旧来および近代のバイオインフォマティクス(生物情報・生命情報)を一元化し、ストレージサイロを統合します。
● ビッグデータ解析
すべての研究対象データをNVMe速度で分析し、圧倒的なアドバンテージを提供します。
Architectureアーキテクチャー
アクセスパターンやあらゆるワークロードに対して最適化された次世代アーキテクチャー
VAST Dataはあらゆるアクセスパターン(ランダム or シーケンシャル)、ワークロード(Write/Read インテンシブ)、ブロックサイズ(スモール or ラージ)に対応し、最適なパフォーマンスを提供できるストレージソリューションです。エンタープライズインフラでの活用はもちろん、ビッグデータやAI基盤での活用、バックアップ・リカバリ分野など、その用途は多岐にわたります。

基本構成
VAST Dataは従来のHead-Shelf型やHCI型のストレージとは構造が異なり、性能を司るコンピュートボックス(C-BOX)、容量を司るデータボックス(D-BOX)、それらのネットワークをバックエンドで結合するNVMeスイッチの3つのコンポーネントから構成されます。性能と容量を分離することでこれまでにない拡張性を実現します。
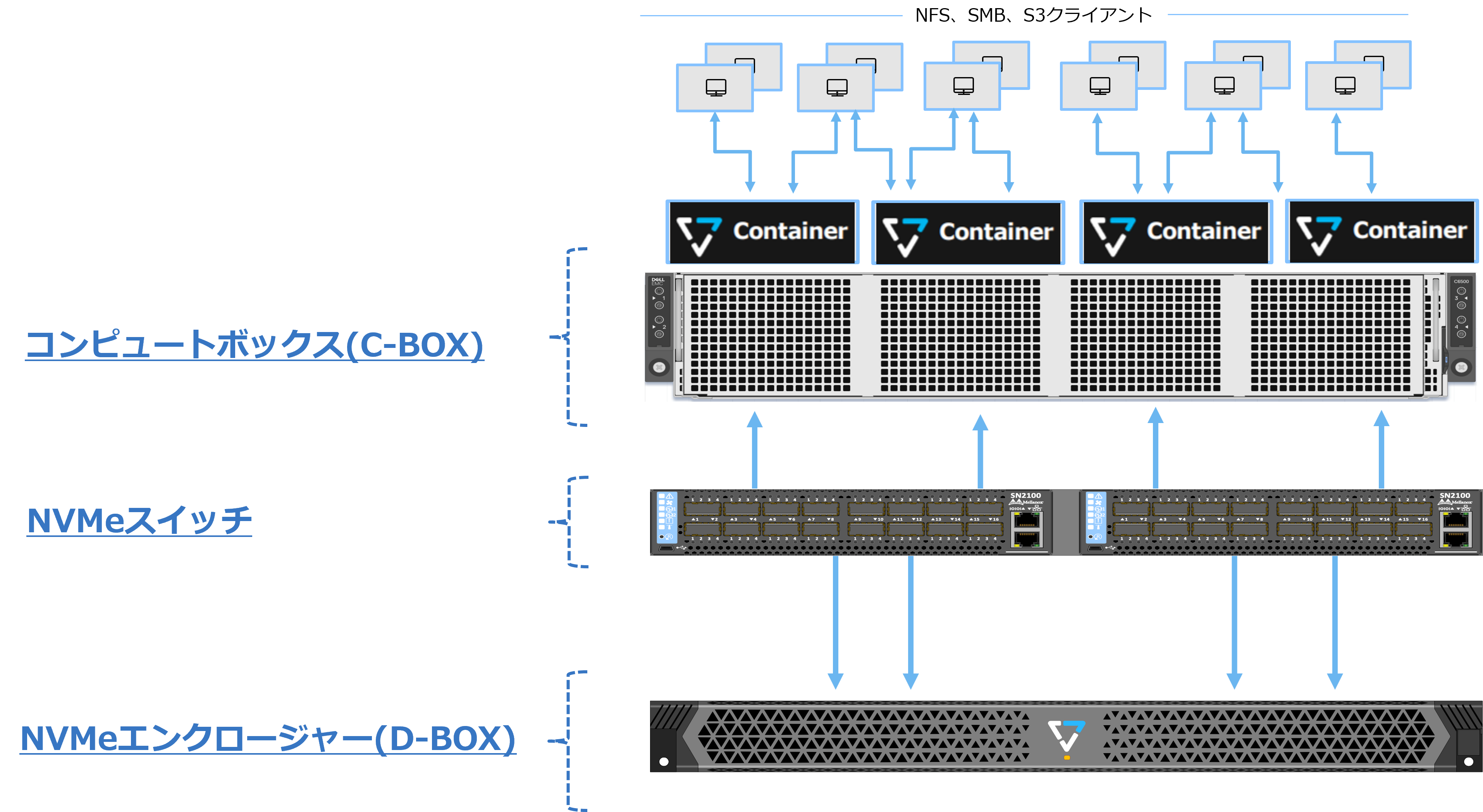
圧倒的コストパフォーマンスと柔軟な拡張性
VAST Dataの基本概念である非統合・全共有(DASE)のデータアーキテクチャーは、性能と容量を完全に分離することで、ペタバイト(PB)~エクサバイト(EB)クラスまでの拡張を容易に実現し、これまでのストレージソリューション最大の課題であったコストとパフォーマンスという相反するニーズの両方を実現します。すべてのデータとアプリケーションにとって柔軟な拡張性と最適なパフォーマンスを提供可能で且つ、従来のHybridストレージ並みのコストで導入可能です。
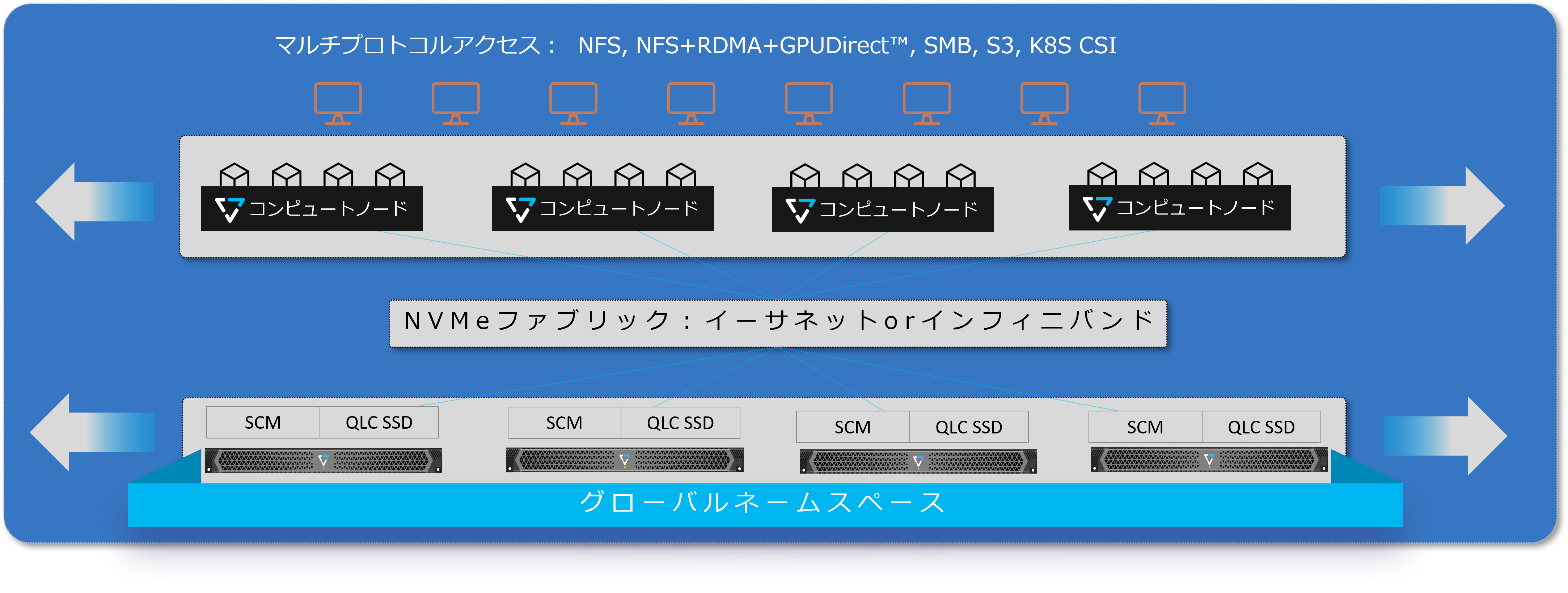
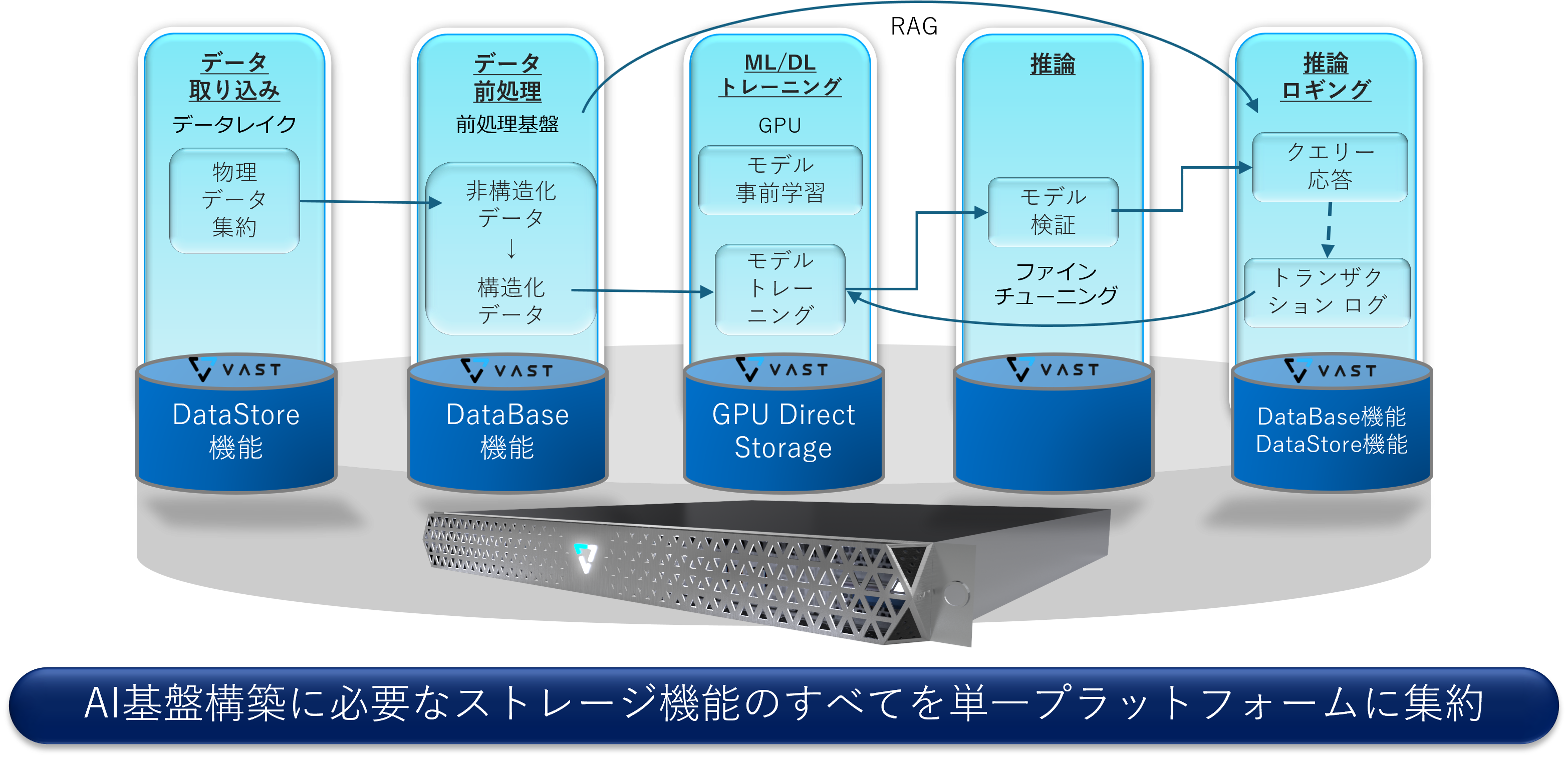
Visionビジョン
AI活用を見据えて設計された単一のスケーラブルなプラットフォーム
VAST Dataが提供するプラットフォーム上ではAI活用を見据えて設計されています。
これまでデータレイクに収集した構造化・非構造化データの中から非構造化データを抽出し、トレーニング可能な構造化データ化をしたうえでGPU Directストレージへ移行、トレーニングを実施するというプロセスが必要だと考えられていましたが、VAST Dataはそのすべてを単一のプラットフォーム上で完結させるアーキテクチャーを持っており、ストレージの統合と運用コストの削減を実現します。
Feature特長
10年間の超長期保守を実現
10年一括の長期保守提供により、従来数年に1度対応が必要だったデータ移行費用を圧縮し、並行稼働期間に発生する重複コストも削減可能です。
QLCの摩耗を最小化する書き込みファイルシステム
VAST Dataに搭載されているSSDはストレージクラスメモリーとQLCフラッシュメモリーの2つに分類されます。すべてのデータの一次受けを高速で摩耗に強いSCMで一次受けし、ある程度のデータの塊になったところで摩耗に弱く安価なQLCへ一回で書き込むことで、QLCの摩耗を最小化することに成功しています。 VAST Dataは安価なQLCを大量に搭載することで、コストとパフォーマンスの両立を実現しています。
VASTの類似性データ削減
従来の方法より1,000倍細かい粒度でパターン検索し、従来のストレージでは実現し得なかった削減率を提供します。従来様々なストレージに実装されていた圧縮・重複排除に加えて、第三の方法として類似性データ削減をサポートしています。この類似性データ削減は従来よりも細かい粒度でデータ削減を行うことで、圧縮済みのLogファイルや画像、映像、データ削減済みのバックアップファイルをさらにコンパクトに格納することが可能です。全世界のVASTユーザーの平均データ削減率は3:1を誇ります。
単一プラットフォーム上でのランサムウェア対策を実現
VAST Dataのセキュアスナップショットの機能を用いると、管理者が指定した任意の期間は例外なく(VAST Dataの管理者権限であっても)削除・改ざんが不可能なスナップショットを取得することが可能です。
これにより、ランサムウェア対策におけるセキュリティレベルの向上を見込めます。
データのロケーションに依存しないデータスペース機能
複数拠点若しくはCloudを含むロケーションにVAST Dataが存在する場合、利用者はデータのロケーションを意識することなくすべてのデータがあたかもローカルにあるかのようにアクセス・編集が可能です。
データの共有・同期の際の競合問題に対してもリアルタイム同期を実現しながらデータの一貫性を担保することが可能です。

Related関連記事
-

Arista Networks
DCネットワークセキュリティ#ディープパケットインスペクション#ネットワークスイッチ -

CIAM Platform
セキュリティ#IDENTITY&ACCESS MANAGEMENT -

DatAdvantage
セキュリティデータマネジメント#ACCESS PRIVILEGE MANAGEMENT#DSPM・CSPM・SSPM#マルウェア対策#ランサムウェア対策 -
DatAlert
セキュリティデータマネジメント -

Zscaler(製品一覧)
セキュリティ -
Zscaler(パートナー一覧)
セキュリティ -
Zscaler Internet Access(ZIA)
セキュリティ#CNAPP#DSPM・CSPM・SSPM#SASE・SSE#セキュアウェブゲートウェイ#マルウェア対策#ランサムウェア対策 -
Zscaler Private Access(ZPA)
セキュリティ#DSPM・CSPM・SSPM#SASE・SSE